构造式隐写是近年来学术界研究的热点,最近的研究表明,由秘密信息直接生成高质量的数字图像是可以实现的。本期介绍9001cc金沙首页多媒体智能安全实验室在ACM MM 2022上录用的两篇论文,采用不同的手段实现了两种构造式隐写方法。
生成式隐写网络
近年来,生成式隐写(generative steganography)成为了一个新兴的研究方向。相比于传统隐写方法,生成式隐写可直接从秘密信息合成含密图像,而无需通过修改载体图像来隐藏秘密信息。在理想条件下,合成的含密图像无需和载体图像进行对比,因此具有较高的安全性。但现有的生成式隐写方法总体性能较差,无论是在隐藏容量、提取准确率,还是在图像质量方面都比传统方法有较大的差距。另外,如果合成的含密图像由于质量较差而被区分出来,生成式隐写带来的理论安全性也不复存在。为了解决上述问题,我们提出了一种高性能的生成式隐写网络。
主体框架:
如图1所示, 该网络由四个子网络组成,即生成器、判别器、隐写分析器和提取器。他们分别用来合成含密图像、保证图像质量、减小统计分析差异和提取秘密信息。由于合成的含密图像和真实图像之间始终存在一定差异。为了对抗隐写分析,我们希望生成器G能够生成难以区分的cover和stego图像。如图所示,当潜变量z 和随机噪声n 输入时,G 合成不含密的cover图像;当潜变量z和二进制秘密信息d输入时,G能够合成含密stego图像。在每次迭代时,G合成若干组cover/stego图像。其中,stego图像和真实图像输入判别器D进行判别,用于保证图像的质量。Cover和stego图像输入到隐写分析器S中,以减少他们之间的统计差异。我们分别采用了一个判别器D和隐写分析器S,是因为D主要通过提取低频信息来进行图像判别,而S通过提取高频信号来进行隐写分析。含密stego图像被送入到提取器E中,用来提取隐藏的秘密信息。我们在隐藏信息和含密图像之间引入了互信息,通过对G和E进行蒙特卡洛模拟和联合优化,有效的提高了隐藏信息的提取准确率。
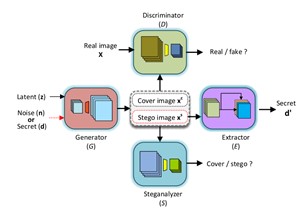
图1. GSN总体框架图
现有方法多采用映射规则, 通过GANs来合成图像。但由于latent z 或者图像标签y的尺寸限制,这类方法隐藏容量通常较低。如果增大它们的尺寸,网络会变得很难训练,并且图像质量会大幅下降。与现有方法不同,我们选择了在图像生成过程中隐藏信息,这极大提高了信息隐藏容量并获得高质量图像。生成器结构如图2所示, 在原有的stylegan2基础上,我们增加了secret block 模块。为了能够同时生成cover/stego图像,我将高斯噪声n和二进制秘密信息张量d 分别加到卷积特征图上。加入的高斯噪声可以增强图像细节。输入的秘密信息张量尺寸为B×H×W, 这里通道B决定了信息的最大隐藏容量。由于加入了高斯噪声和二进制数两种不同信号,我们增加了一个低通滤波器来消除高频噪声、黑点等缺陷。
信息隐藏和提取:
在文中,我们通过在图像生成过程中添加噪声或二进制秘密信息,分别生成了cover、stego两种图像。两种图像极其相似,通过肉眼和普通隐写分析方法都难以区分。训练完毕后,发送者可使用G生成含密图像,并通过无损信道发送;接收者收到含密图像后,可使用E提取出隐藏的秘密信息。由于两类图像难以区分,发送者可同时发送含密和不含密的图像,以迷惑对手。接收者使用E能从含密图像中准确提取信息,而从非含密图像中提取不到任何有用信息。虽然我们生成的含密图像与真实图像比尚有差距,但是通过合成含密和非含密两种图像有效增加了隐蔽通信的安全性。此外,为了提高抗隐写分析能力,我们开发了一个梯度层次递减(GHD)技巧。
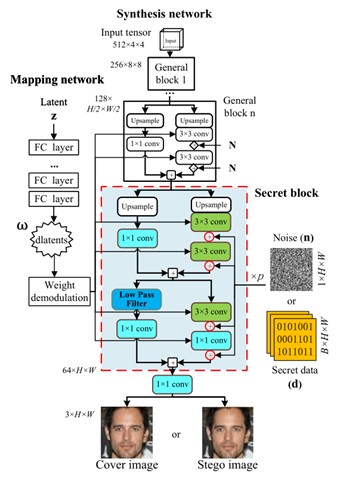
图2.生成器G的结构
性能表现:
我们在CelebA和 Bedroom 两个数据集上进行了测试。总体性能如表1所示,通过改变输入秘密信息的通道数B,我们得到了不同容量含密图像的总体性能。随着负载增加,秘密信息提取准确率和图像质量均逐渐下降,但是抗隐写分析指标Pe均稳定在0.5左右。当payload在1 bpp 时,提取准确率在97%以上,在图像质量和安全性上均表现较佳。图3和图4为合成的高质量含密图像样本。
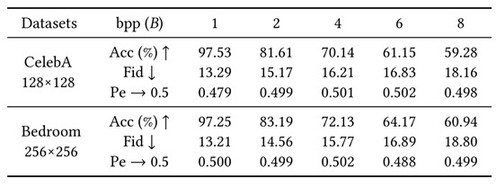
表1·提出GSN性能

图3.合成的含密人脸图像(从上到下每行图像payload 分别为1、2、4、6、8 bpp )

图4.合成的含密卧室图像(从左到右每栏中图像payload 分别为1、2、4、6、8 bpp )
性能对比:
我们分别与基于深度学习的载体修改式隐写方法(DL-based TS),定制化生成式隐写方法(Tailored GS,合成纹理、指纹等类型含密图像)和基于深度学习的生成式隐写方法(DL-based GS)进行了对比,结果如表2所示。除Hidden外,DL-based TS方法总体隐写安全性较差,Pe都接近于0。Tailored GS 方法信息隐藏能力低,且只能生成特定类型的含密图像。在基于深度学习的隐写(DL-based GS)方法中, 我们方法在各项性能上均取得了大幅领先。
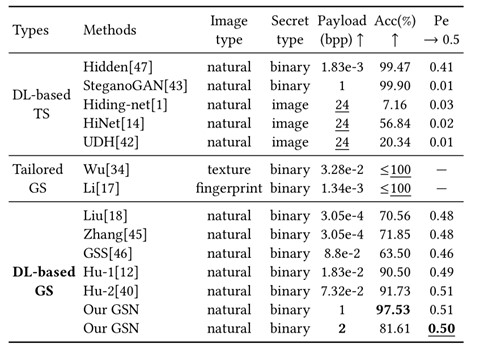
表2·与现有方法性能比较
论文信息:
Ping Wei, Sheng Li, Xinpeng Zhang, Ge Luo, Zhenxing Qian, and Qing Zhou. 2022. Generative Steganography Network. In Proceedings of the 30th ACM International Conference on Multimedia (MM ’22), October 10–14, 2022, Lisbon, Portugal. ACM, New York, NY, USA.
(论文连接:https://arxiv.org/pdf/2207.13867.pdf)
社交网络中隐秘传输图像生成网络
传统隐写方法会造成图像像素值的修改,学者们提出构造式隐写来避免这种修改。然而,现有的方法生成的图像质量较低,并且大多数方法没有考虑噪声的影响,在JPEG压缩等噪声干扰后,秘密信息不能提取出来。社交网络的兴起使得信息传递更为方便,这种有噪声的信道给信息隐藏带来了新的机遇和挑战。在本文中,我们提出了一个新的鲁棒的构造式信息隐藏模型,我们的模型根据需要传输的秘密信息,直接生成一张图片,并且可以抵抗JPEG压缩的攻击,接收方可以直接根据这张图片提取出秘密信息。另外,我们发现在社交网络上,表情包和头像被人们广泛使用,如果以这种常见的形式传递秘密信息,会进一步降低攻击者的怀疑,因此我们考虑生成人脸图像和表情包来进行传递秘密信息。
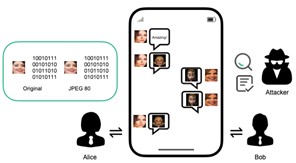
我们的模型分为生成器、鉴别器、提取器、噪声模块四个部分,模型以生成对抗的方式进行训练。为了抵抗JPEG等攻击,我们考虑从语义角度进行秘密信息的传递,因为大多数的语义信息在这些攻击后仍能保持不变。本文中,我们使用了图像生成器的归一化操作所需要的scale和bias来进行秘密信息的嵌入。我们在模型中加入了噪声模块一起训练,由于JPEG操作是不可导的,不能直接加入到网络中,我们将经过JPEG压缩后的图像与原图做差,将之作为常数加到原图上。对于表情包图像的生成,我们使用了FERG-DB数据集,这个数据集包括了6个卡通人物,每个卡通人物有7种表情,可选的表情向量可以控制生成图像的表情。对比现有的几种构造式隐写方法,Generative Steganography Network(MM2022)中提出利用图像生成过程中添加的随机噪声进行嵌入,Image Disentanglement Autoencoder for Steganography Without Embedding(CVPR2022)中提出使用结构张量进行秘密信息的嵌入,本文则使用归一化操作所需要的参数来代表秘密信息。这三种方式分别对应Style-GAN中不同的输入,通过控制生成器的不同部分来合成含密图像。

我们使用了FID来评估图像生成的质量,结果显示,我们图像的质量较之前方法更优。在鲁棒性方面,训练阶段,我们使用了质量因子为90、80、70、60、50的JPEG压缩,在测试时质量因子采用90、80、70、60、50、95、85、75、65、55,均能取得较高的提取准确率。另外,我们还考虑了一些常见的图像操作,如模糊、旋转、噪声等,我们的模型也能够抵抗这些攻击。在安全性方面,由于我们使用的图像尺寸较小,只需要很少的显存就可以训练,我们可以使用不同数据集、网络结构生成新的隐写模型。即使攻击者基于已掌握的隐写模型训练网络来判断图像是否含密,在新的隐写模型上很难取得泛化能力。实验表明,我们的模型在图像质量、鲁棒性、安全性方面都有不错的效果。


论文信息:
Zhengxin You, Qichao Ying, Sheng Li, Zhenxing Qian, Xinpeng Zhang. Image Generation Network for Covert Transmission in Online Social Network. In Proceedings of the 30th ACM International Conference on Multimedia (MM ’22), October 10–14, 2022, Lisbon, Portugal. ACM, New York, NY, USA.






