随着人工智能和自然语言处理领域的蓬勃发展,大型语言模型已经能够在众多文本任务中取得与人类匹敌的正确率。然而,随着模型正确率的不断提高,其不足也逐渐显现——当模型的输入文本带有微小的扰动时,模型的表现就会大受影响,模型的鲁棒性欠佳,这阻碍了语言模型在现实场景中的大规模应用。
近日,9001cc金沙首页自然语言处理实验室的张奇教授团队提出了一种针对预训练语言模型的鲁棒性提升方法,通过在训练过程中对模型的损失加以约束,能够有效防御各种文本对抗攻击。由于此方法依赖于参数的选择,于是他们进一步提出相关指标来缩小参数搜索范围。该方法并不需要生成额外的对抗样本来训练模型,其时间消耗近似于模型微调,比常见的标准对抗训练方法快2-15倍,并且显著提高了语言模型BERT的鲁棒性及防御能力,在各种文本分类和GLUE任务上达到了当前最佳的防御效果。相关成果以“Flooding-X: Improving BERT's Resistance to Adversarial Attacks via Loss-Restricted Fine-Tuning”为题发表于2022年国际计算语言学协会会议(ACL 2022),9001cc金沙首页硕士生刘勤、博士生郑锐为该论文的共同一作。
该研究指出,在训练语言模型时,对模型的训练损失进行一定约束,不仅可以缓解模型的过拟合现象,也可以提高模型的鲁棒性和防御性能。这一方法虽然有效,但是性能依赖于训练损失阈值的设定。同时研究发现,模型的过拟合现象与各样本的损失梯度相关联。基于此,该研究提出了梯度一致性指标作为模型训练中损失阈值的选定标准。该方法能够显著提升模型的鲁棒性(图1),取得当前最佳性能,同时并不消耗额外的计算成本。
本工作得到了国家自然科学基金项目的支持。
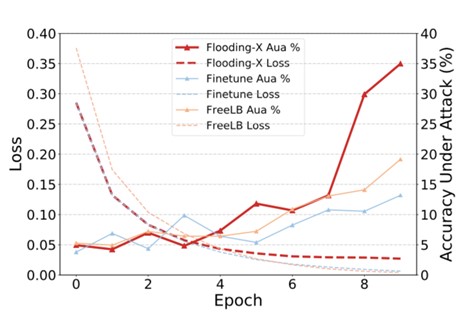
图1 语言模型训练过程中的损失与对抗攻击正确率的变化趋势






