2022年国际多媒体顶级会议ACM Multimedia中,由我院颜波教授和谭伟敏青年研究员带领的9001cc金沙首页数字媒体实验室发表的3篇论文《Geometry-Aware Reference Synthesis for Multi-View Image Super-Resolution》、《Learning Parallax Transformer Network for Stereo Image JPEG Artifacts Removal》和《Co-Completion for Occluded Facial Expression Recognition》入选。ACM Multimedia是计算机学科多媒体领域的顶级国际会议,也是中国计算机学会(CCF)推荐的该领域唯一的A类国际学术会议。
《Geometry-Aware Reference Synthesis for Multi-View Image Super-Resolution》针对多视图多媒体应用难以同时满足用户高分辨率视觉体验和存储、带宽需求等问题,提出了一种多视图图像超分辨率任务,旨在提高从同一场景捕获的多视角图像的分辨率。现存问题的一种解决方案是应用图像或视频超分辨率方法从低分辨率输入视图重建高分辨率结果。然而,这些方法不能处理视图之间的大角度转换,也不能利用所有多视图图像中的信息。为了解决这些问题,该论文提出了MVSRnet,如图(a)所示,它利用几何信息从所有低分辨率多视图中提取清晰的细节,用这些细节来帮助视角图片的超分。具体而言,MVSRnet中提出的几何感知参考合成模块利用几何信息和所有多视图低分辨率图像来合成像素对齐的高分辨率参考图像,如图(b)所示。然后,在MVSRnet中提出的动态高频搜索网络充分利用了参考图像中的高频纹理细节进行多视角图片超分辨率。大量的实验结果表明,该方法明显优于目前最先进的单图、视频、有参考超分辨率方法。

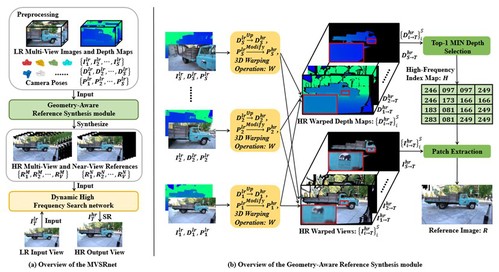
图1 算法框架图
《Learning Parallax Transformer Network for Stereo Image JPEG Artifacts Removal》提出了一种利用Parallax Transformer进行左右视图特征匹配的网络,能够有效去除立体图像压缩噪声。近些年,立体图像处理由于巨大的商业价值受到广泛的关注。在实际中,通常采用图像压缩算法(JPEG)来保存立体图像,这不可避免地引入压缩噪声。因此,该论文提出了PTNet,通过Parallax Transformer对左右视图特征进行匹配,该匹配对压缩噪声具有鲁棒性。此外,由于遮挡、边界等因素,PTNet进一步提出了基于置信度图的自适应特征融合方法。具体来说,PTNet利用Parallax Transformer来提取特征匹配的相似度,并将相似度值作为匹配的置信度,然后利用该置信度图融合两个视角的特征,以降低遮挡的影响。大量的实验结果表明,与最新的单图压缩噪声去除方法和立体超分算法相比,该论文方法在立体图像噪声去除任务上表现出明显优势。同时,可以有效提升立体图像在视差估计任务上的性能。

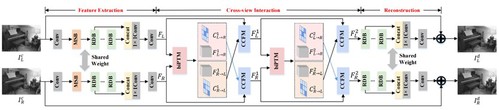
图2 算法框架图
《Co-Completion for Occluded Facial Expression Recognition》提出了一种基于协同补全的有遮挡人脸表情识别方法,能够在检测遮挡物的同时对人脸表情进行识别。遮挡物的存在,破坏了图像中人脸的结构完整性、引入了语义无关的视觉模式并导致了被覆盖区域的信息缺失,从而限制了相关算法在真实场景中的应用。一种直观的解决方法是对有遮挡图像进行盲修复,而后进行表情识别。然而此种方法存在过程冗余、耦合度高等缺点,且盲修复网络在真实遮挡图像上表现不佳。为此,该论文提出了Co-Completion方法,它对上述方法进行流程优化,通过联合遮挡物抠除与特征补全以抑制遮挡物干扰、提升识别精度。大量实验结果表明,该论文提出的方法在合成和真实遮挡数据集上都能够达到最好或与其他识别算法相当的识别精度。

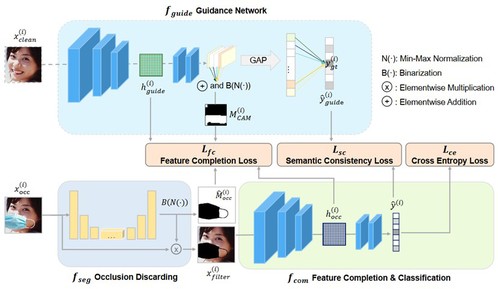
图3 算法框架图






